DexLite: Replicating State-of-the-Art Dexterous Grasping (On a Budget)
Note: This project is an implementation of the grasp synthesis methodology presented in the paper Dex1B: Learning with 1B Demonstrations for Dexterous Manipulation. The neural network architecture and energy functions described herein are based on their published work.
Abstract: This post details my journey building DexLite, a learning-based system for synthesizing dexterous grasps on a Shadow Hand. By adapting the massive-scale Dex1B pipeline for a standard laptop GPU, I explore the intersection of generative deep learning and physics-based optimization.
The "Fine, I'll Do It Myself" Moment
A few months ago, researchers from UC San Diego released a fascinating paper titled Dex1B: Learning with 1B Demonstrations for Dexterous Manipulation. It proposed a massive-scale approach to learning dexterous manipulation, utilizing a dataset of one billion demonstrations to solve complex grasping and articulation tasks.
I read it, thought it was brilliant, and immediately went hunting for the code. Result: No code online.
So I decided to implement the paper myself, atleast whatever I could in simulation. I wanted to understand the nuts and bolts of how they achieved such high-quality results by combining optimization with generative models. I call my implementation DexLite—a lightweight, accessible version of their massive pipeline (some corners were cut because of hardware constraints).
The Challenge: High-DOF Grasping
Why is this hard? Unlike a simple parallel-jaw gripper, the Shadow Hand possesses high degrees of freedom (DoF), making it incredibly challenging to control effectively. It is essentially a human hand.
Mathematically, given an object represented by a point cloud , we need to find a hand configuration that results in a stable, force-closure grasp:
where is the wrist translation, is the wrist rotation (Euler angles), and contains the 22 joint angles for the Shadow Hand's fingers.
Finding a valid configuration for these 28 parameters that results in a stable grasp is an optimization problem which is very slow for generating large datasets. The Dex1B paper solves this by identifying two key issues in generative models: feasibility (lower success rates) and diversity (tendency to interpolate rather than expand).
How DexLite Works
My implementation follows the core philosophy of the paper, integrating geometric constraints into a generative model. The pipeline consists of three main stages:
-
The Neural Network: The heart of the system is a conditional generative model. It starts with PointNet, which processes the object's point cloud to extract global geometric features and local features for specific surface points.
PointNet uses a hierarchical architecture with 1D convolutions (3→64→128→1024→256 channels) followed by symmetric max pooling to achieve permutation invariance:
These features are fed into a Conditional Variational Autoencoder (CVAE), which learns the conditional distribution of grasps given object geometry.
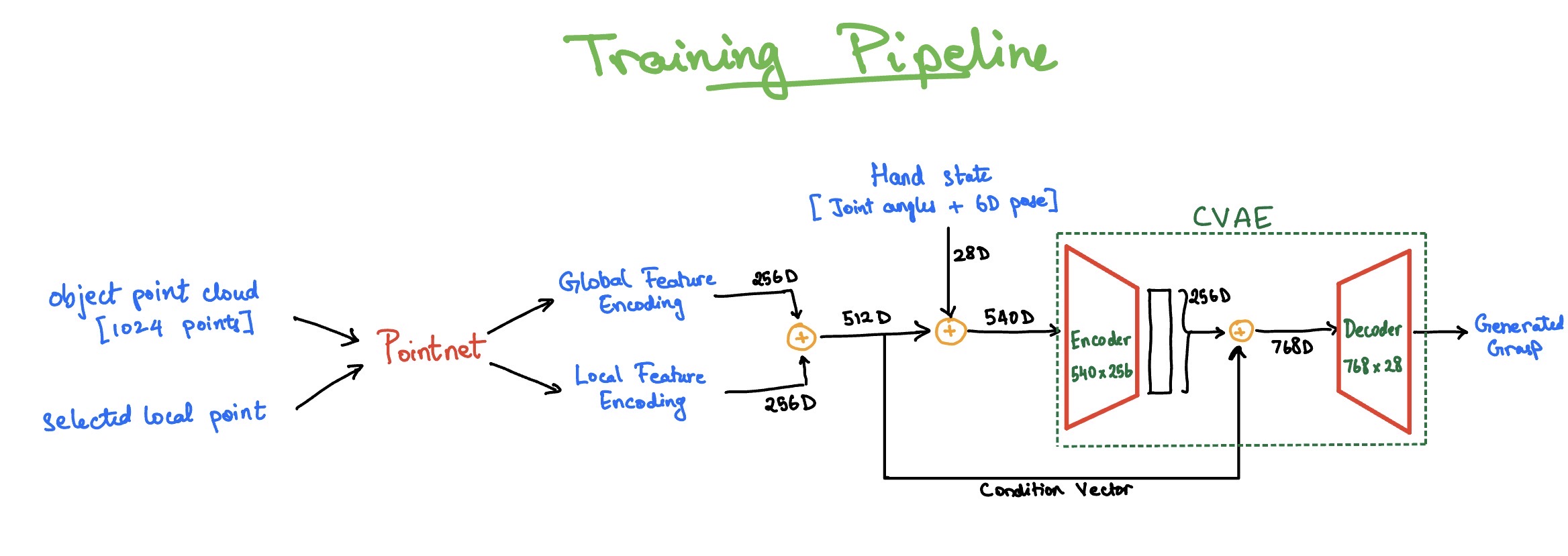
The CVAE uses the reparameterization trick to enable backpropagation:
Encoder (training only):
Sampling: , where
Decoder:
The CVAE structure allows for two distinct modes of operation:
- Dataset Expansion: During training, we can input existing valid grasps along with the object features into the Encoder to map them to a latent space. By slightly varying the "associated point" (the target point on the object where the grasp approaches from) or the latent vector, we can decode variations of known successful grasps, effectively multiplying our dataset.
- Pure Synthesis: For generating completely new grasps at inference time, we bypass the Encoder entirely. We sample random noise and feed it into the Decoder along with the object features. The Decoder then "hallucinates" a valid grasp configuration from scratch.
-
The Losses: You can't just train this on visual similarity (MSE) alone. To ensure the generated hands don't look like spaghetti or clip through the object, I implemented a comprehensive set of energy functions:
-
Reconstruction Loss: - Keeps the generated grasp close to the ground truth during training.
-
KL Divergence: - Regularizes the latent space so we can sample from it later.
-
Force Closure: - Ensures the grasp is physically stable and resists external wrenches. Here is the grasp matrix that maps contact forces to object wrenches:
where is the skew-symmetric matrix for the cross product at contact point .
-
Penetration Penalty: - Uses Signed Distance Functions (SDF) to punish fingers for clipping inside the object mesh. The +1 provides a safety margin.
-
Contact Distance: - Acts as a magnet, pulling fingertips towards the object surface to ensure contact. is the signed distance from contact point to the nearest object surface.
-
Self-Penetration: - Prevents the hand from colliding with itself, where is the minimum distance between finger links and .
-
Joint Limits: - Ensures the hand doesn't bend in physically impossible ways.
The total training loss combines all these terms:
I used weights of , (to prevent posterior collapse), , , , , and .
-
-
Post-Optimization: A final optimization step that fine-tunes the fingers to ensure solid contact, minimizing the energy function .
Key Implementation Differences (The "Lite" Part)
The original Dex1B pipeline is designed to generate one billion demonstrations using massive compute clusters. My constraints were slightly different: I am running this on a laptop with an RTX 4050.
To make this feasible, I had to be smarter about my data:
-
Curated Data vs. Raw Generation: The paper generates a seed dataset of ~5 million poses using pure optimization. Instead of burning my GPU for weeks, I curated a high-quality subset from the existing DexGraspNet dataset.
-
Rigorous Filtering: I built a custom validation pipeline using PyBullet and MuJoCo:
- Stability Test (PyBullet): Objects must remain stable on a table after 2 seconds of simulation. Criteria: lateral displacement m and angular change . This filtered out ~45% of objects (spheres, thin plates, etc.), leaving ~3,000 stable objects from the original ~5,500.
- Lift Test (MuJoCo): Each grasp is tested by lifting the object 1m upward. Success requires lift ratio :
This achieved a ~90% pass rate on ~550,000 grasps, yielding ~495,000 high-quality training examples.
The Secret Sauce: Post-Optimization
Here was a big takeaway from this project: NO matter what, The neural network is not enough.
The raw output from the CVAE is good, but often suffers from lower success rates than deterministic models. It gets close to a successful grasp, but doesn't achieve it. Maybe it penetrates, or maybe it does not make contact. But tiny adjustments can make it successful.
I implemented the post-optimization step suggested in the paper. It takes the sampled hand poses and refines them using gradient-based optimization of the same energy function:
The optimization uses RMSProp with simulated annealing to escape local minima:
with acceptance probability and temperature decay (parameters: , , ).
I run 200 iterations of this optimization, which takes only ~2 seconds per grasp compared to minutes for optimization from scratch. The results speak for themselves:
- Raw Network Output: ~55% Success Rate (Grasps often loose or clipping).
- With Post-Optimization: ~79% Success Rate (Tight, physically valid grasps).
As the paper notes, this hybrid approach leverages the best of both worlds: optimization ensures physical plausibility, while the generative model enables efficiency and provides semantically meaningful initializations that converge ~3x faster than random starts.
Conclusion & Future Work
Replicating Dex1B was a lesson in the importance of hybrid approaches. Deep learning provides the intuition, and classical control theory provides the precision.
I’m planning to extend this work by incorporating "Graspness" (learning which parts of an object are graspable) and potentially moving to dual-hand manipulation.
Appendix: Hyperparameters
Network Architecture
PointNet:
| Layer | Input Channels | Output Channels | Activation |
|---|---|---|---|
| Conv1 | 3 | 64 | ReLU + BN |
| Conv2 | 64 | 128 | ReLU + BN |
| Conv3 | 128 | 1024 | ReLU + BN |
| Conv4 | 1024 | 256 | BN (no activation) |
| Max Pool | 256 | 256 | Global max over points |
CVAE Encoder:
| Layer | Input Dim | Output Dim | Activation |
|---|---|---|---|
| FC1 | 540 (28 + 512) | 256 | ReLU |
| FC2 | 256 | 512 | ReLU |
| FC3 | 512 | 256 | ReLU |
| FC_μ | 256 | 256 | None |
| FC_σ | 256 | 256 | None |
CVAE Decoder:
| Layer | Input Dim | Output Dim | Activation |
|---|---|---|---|
| FC1 | 768 (256 + 512) | 256 | ReLU |
| FC2 | 256 | 512 | ReLU |
| FC3 | 512 | 256 | ReLU |
| FC_out | 256 | 28 | None |
Training Hyperparameters
| Parameter | Value | Description |
|---|---|---|
| Batch Size | 64 | Number of samples per batch |
| Learning Rate | 0.0001 | Adam optimizer learning rate |
| Epochs | 100 | Total training epochs |
| Latent Dimension | 256 | Dimension of latent space |
| Point Cloud Size | 2048 | Number of points sampled from object |
Loss Weights
| Weight | Value | Purpose |
|---|---|---|
| 1.0 | Reconstruction fidelity | |
| 0.001 | Latent space regularization | |
| 1.0 | Force closure constraint | |
| 100.0 | Contact distance penalty | |
| 100.0 | Object penetration penalty | |
| 10.0 | Self-penetration penalty | |
| 1.0 | Joint limit violation penalty |
Post-Optimization Parameters
| Parameter | Value | Description |
|---|---|---|
| Iterations | 200 | Number of optimization steps |
| Step Size () | 0.005 | Initial learning rate |
| RMSProp Momentum () | 0.98 | Momentum for squared gradient |
| RMSProp Epsilon () | Numerical stability constant | |
| Initial Temperature () | 18 | Starting annealing temperature |
| Temperature Decay () | 0.95 | Decay factor per period |
| Annealing Period () | 30 | Steps between temperature updates |
| Contact Switch Probability | 0.5 | Probability of switching contact points |